
The Engineering Tax: What Your Build Decision Actually Costs

I stopped seeing build versus buy as a procurement decision when I realized AI had turned it into a question of who owns the adaptation burden.
Once a system sits inside your firm's core workflows and has to keep learning, staying accurate, and staying trusted, you're not making a sourcing choice anymore. You're making an operating model decision.
After more than 25 years in consulting, I've watched the same pattern play out across dozens of firms. Different conversations, different contexts, same symptoms. Firms burning time and money stitching together fragmented tools, manually curating knowledge, and forcing generic systems into consulting-specific workflows they were never designed for.
That's what I call the Engineering Tax.
It's the hidden cost of building and maintaining infrastructure that feels strategic but often just recreates capabilities that should already exist. The tax shows up in long implementation cycles, integration complexity, maintenance overhead, and internal engineering effort spent on plumbing instead of solving the actual business problem.
The Build Trap Lifecycle
The pattern usually starts the same way. Someone says, "We should build this because our workflows are unique."
That instinct is understandable. Consulting firms want domain-specific language, custom workflows, and more control than generic copilots offer.
Stage one is ambition. The team defines a real pain point: fragmented workflows, scattered knowledge, and the inability to turn firm expertise into something consultants can actually use in client work.
Stage two is architecture. This is where scope quietly expands. What sounds like a knowledge solution becomes a broader infrastructure project involving data management, cloud setup, security, compliance, integrations, and technical readiness.
Stage three is integration. Now you're connecting CRM, project management, communication tools, documents, databases, and other SaaS systems. This is often where the first real friction appears. Data silos, inconsistent formats, and workflow disruption start slowing everything down.
Stage four is when it becomes a platform nightmare.
The system now has to connect multiple enterprise systems while staying secure, compliant, and reliable. Deep integration is valuable, but integration challenges can disrupt established workflows and create dissatisfaction if they're not seamless.
At the same time, the knowledge layer itself starts demanding care and feeding. Traditional repositories become outdated. Manual curation creeps back in. Data silos and inconsistent formats degrade output quality. Teams discover that keeping knowledge current is harder than shipping the first version.
What Breaks First When Ownership Fragments
What usually breaks first is not the model itself but the maintenance loop around it.
Taxonomy updates, source connections, relevance tuning, training, and day-to-day workflow fit all stop getting coordinated once the original champion leaves. The system may still technically run, but it quickly loses freshness, trust, and usability.
The first visible failure is content freshness and retrieval quality. Traditional knowledge bases become outdated. Manual curation is burdensome. Data quality, silos, and inconsistent formats undermine retrieval. When no one is actively curating or governing the system, answers become less reliable almost immediately.
The second failure is integration hygiene. When the original builder leaves, connector issues, schema changes, permissions drift, and workflow disruptions no longer have a single owner. Deep integrations with CRM, project management, communication tools, and other repositories become fragile instead of seamless.
Here's a concrete example:
A consulting firm builds an internal AI knowledge layer that pulls from proposals, project deliverables, emails, meeting recordings, databases, and SaaS tools. One senior builder informally owns the taxonomy, relevance logic, source priorities, and user feedback loop.
When that person leaves, engineering assumes the platform is stable. IT assumes it's just another integration stack. Practice leaders assume the knowledge layer will keep improving on its own.
Within a few weeks, a source system changes structure. A permission breaks. A few high-value project artifacts stop flowing into the system. The AI still answers questions, but it now misses recent case work, overweights older material, and starts surfacing outputs that feel generic or incomplete.
This is exactly the kind of degradation that happens when outdated repositories, fragmented systems, and insufficient context collide.
The Compound Costs Nobody Budgets For
The compounding costs are usually not just technical debt. They're trust debt, workflow debt, and governance debt that quietly grow after launch.
Knowledge quality decays first. Traditional knowledge bases become outdated. Data lives in silos. Teams start getting incomplete or stale answers, which forces more manual cleanup and reduces confidence in the system.
Integration debt grows next. Once the system touches CRM, project management, and communication tools, even small schema or workflow changes can create friction, break usability, and require ongoing rework that was not in the initial budget.
User trust erodes when the system cannot explain its answers or provide traceability. This later forces teams to add audit logs, transparency controls, and governance processes just to make the output acceptable for real work.
Adoption becomes a cost center. Resistance to change, training, customer support, and continuous upskilling all expand over time, especially when the system becomes part of daily operations rather than a one-off tool.
The expensive part is not keeping the software running. It's keeping the knowledge current, the integrations stable, the answers trustworthy, and the organization willing to rely on it.
Once that internal build becomes embedded in core workflows, every drop in quality or compliance readiness starts to affect onboarding, client delivery, and decision-making. That's when a project turns into costly infrastructure.
The Compliance Tax Nobody Mentioned
A classic surprise tax is the provenance challenge.
Months after launch, legal, risk, or a major client asks the team to prove exactly which documents, decisions, and data sources informed each AI answer. Trust depends on transparency, explainability, and full traceability of outputs.
For example, a partner uses the system to draft client advice. Then compliance asks for source-level citations, decision logs, audit trails, and evidence the answer did not rely on stale, biased, or unauthorized data.
Suddenly the team has to retrofit logging, access controls, explainability layers, and governance workflows that were never on the original roadmap.
That's when the cost equation changes. What looked like a knowledge tool now has to behave like an auditable system of record in order for users to actually trust it.
Companies spend an average of $3.5 million annually on regulatory security compliance. But non-compliant organizations end up paying nearly triple, reaching $9.4 million due to business disruptions and legal settlements.
Regulatory compliance, such as HIPAA or financial regulations, can increase software development costs by 20–50%.
The Real Decision Framework
If I'm sitting across the table from a CTO or partner who's about to greenlight an internal build for a knowledge management system, I ask one question:
"Who will still own the quality, freshness, integrations, and user trust of this system 18 months after the champion leaves—and what's your plan if that person is not engineering?"
That question usually makes people pause because most teams have thought about the build, but not the ongoing manual curation, integration drift, training, governance, and support required to keep a knowledge system relevant and trusted over time.
How to Actually Quantify the Engineering Tax
I compare four buckets:
Build cost: Engineering, infrastructure, third-party tools
Operating cost: Maintenance, support, training, governance
Delay cost: Months of slower time-to-value
Productivity cost: Hours consultants still lose to fragmented workflows while the system is being built
The hidden costs usually show up in the second and third buckets. Manual curation, integration drift, user support, compliance, and the fact that DIY knowledge graph builds are resource-intensive and slower to deliver value, while prebuilt platforms can connect in days and start reducing search time immediately.
The simple calculation is:
(12–24 month total build + run cost) + (value lost during delay)
versus
(subscription + onboarding) − (time and productivity gains captured sooner)
Add the opportunity cost of having resources focus elsewhere, and the math usually tilts decisively.
According to a McKinsey-Oxford study, IT projects had a cost overrun of $66 billion—more than the GDP of Luxembourg. Projects that continue longer are more likely to exceed budget and defined timelines.
Only about 35% of IT projects are delivered on time, on budget, and with their full original scope intact. The other 65% represent normalized organizational dysfunction.
When the Project Becomes a Platform
A project becomes a platform the moment it stops solving one workflow and starts becoming a dependency inside many workflows.
When it's embedded in CRM, project management, and communication tools. When it serves as a central hub for institutional memory. When teams expect it to be available as part of daily operations rather than as an optional tool.
The real line is crossed when an outage, bad answer, or governance failure would no longer just break one use case, but would disrupt how the organization works, makes decisions, or stays compliant.
Now you're maintaining infrastructure, not shipping a feature.
A concrete example: a knowledge assistant evolves from helping a proposal team find past materials into the system partners, delivery teams, and new hires all rely on for proposals, onboarding, and client work. At that point it has become part of the firm's operational backbone.
Where Risk Should Actually Live
The decision is about where you want to carry risk in your stack.
It means deciding which uncertainties you want to own internally—model quality, compliance, integrations, uptime, auditability, and ongoing maintenance—and which ones you want a vendor to absorb because they already have the product, controls, and support in place.
Carry the build risk when the capability is truly core IP and gives you a lasting competitive edge.
Transfer it to a vendor when the problem is important but not differentiating, especially if the internal version would be slow, resource-intensive, and hard to govern.
For example, it makes sense to buy a knowledge system if your firm mainly needs fast deployment, traceability, and integration into CRM and project workflows.
It can make sense to build if your proprietary methodology itself is the product and no vendor can model it well enough.
When Building Actually Makes Sense
I recommend building only when three conditions are true at once:
No vendor can match your domain-specific methodology or assurance requirements
The capability will sit at the center of core operations rather than act as a point solution
You can deliver something trustworthy, integrated, and governable fast enough that speed-to-value does not collapse
If it's not a true source of differentiation, or if getting there means months of setup, integration work, and model-risk management, buying is usually the better strategic choice.
According to Forrester research, 67% of software projects fail because of wrong build versus buy choices. Avoiding this fate requires a nuanced approach beyond simplistic cost comparisons.
What I've Learned the Hard Way
A few years ago, we tried to build a client portal. The irony was not lost on me—we were in the portal business.
What we realized is that the consulting team was good at serving clients, but internal time conflicts and other issues kept getting in the way. The internal team kept getting pulled into client delivery, so the project plan drifted constantly.
The key challenge was that internal teams keep getting pulled into client delivery, so the project plan drifts constantly.
Early on, one client told us they were going to build it themselves. But once they got into it, they realized the problem was far larger than they had scoped. The solution needed to perform in high-stakes scenarios, not just in a demo environment. DIY approaches in this category often become time and resource-intensive faster than expected.
What really changed their mind was recognizing they were not just building a feature. They were taking on complex infrastructure, ongoing accuracy demands, and the burden of keeping the system reliable as workflows and requirements evolved.
Nine months later, they came back to us because the internal path was not delivering the level of trust, context, and operational readiness they originally envisioned.
They realized they could have gotten to the value phase sooner.
The Market Has Already Shifted
In 2026, the decision has shifted from "Build versus Buy" to "Own versus Orchestrate."
Most enterprises land on "yes to both" by buying the heavy core and building what differentiates.
The best ISVs in 2026 are the ones with the discipline to say no to building everything. Do fewer things in-house but do them exceptionally well. Be the best in the world at 3-5 core capabilities and buy or partner for everything else.
McKinsey analysis shows that companies focusing on strategic technology investments achieve 20% higher revenue growth than their peers. The key is knowing what qualifies as "strategic."
First movers can claim almost 70% of market share for new products, but only 20% if that product already exists in the market. The window for differentiation closes fast.
What Makes This Framework Different
Classic build-versus-buy asks, "Which is cheaper or more customizable today?"
This framework asks, "Who should carry the adaptation burden in an AI market that is moving under your feet?"
AI changes the game in two opposite ways at once. It makes initial building faster through prebuilt cloud and AI tooling, but it also makes the system age faster because models, governance expectations, integrations, and user expectations keep shifting.
The distinct angle is not build-versus-buy as a one-time sourcing choice. It's build-versus-transfer as an ongoing risk allocation decision.
In most cases, vendors are better positioned to absorb the constant updating, continuous learning, integration upkeep, and compliance hardening that AI systems now require.
You should only build when the capability is truly core and you can turn it into a trustworthy operational advantage quickly.
The Bottom Line
If your team is investing months of engineering effort just to make the foundation usable, you're probably paying a tax, not building an advantage.
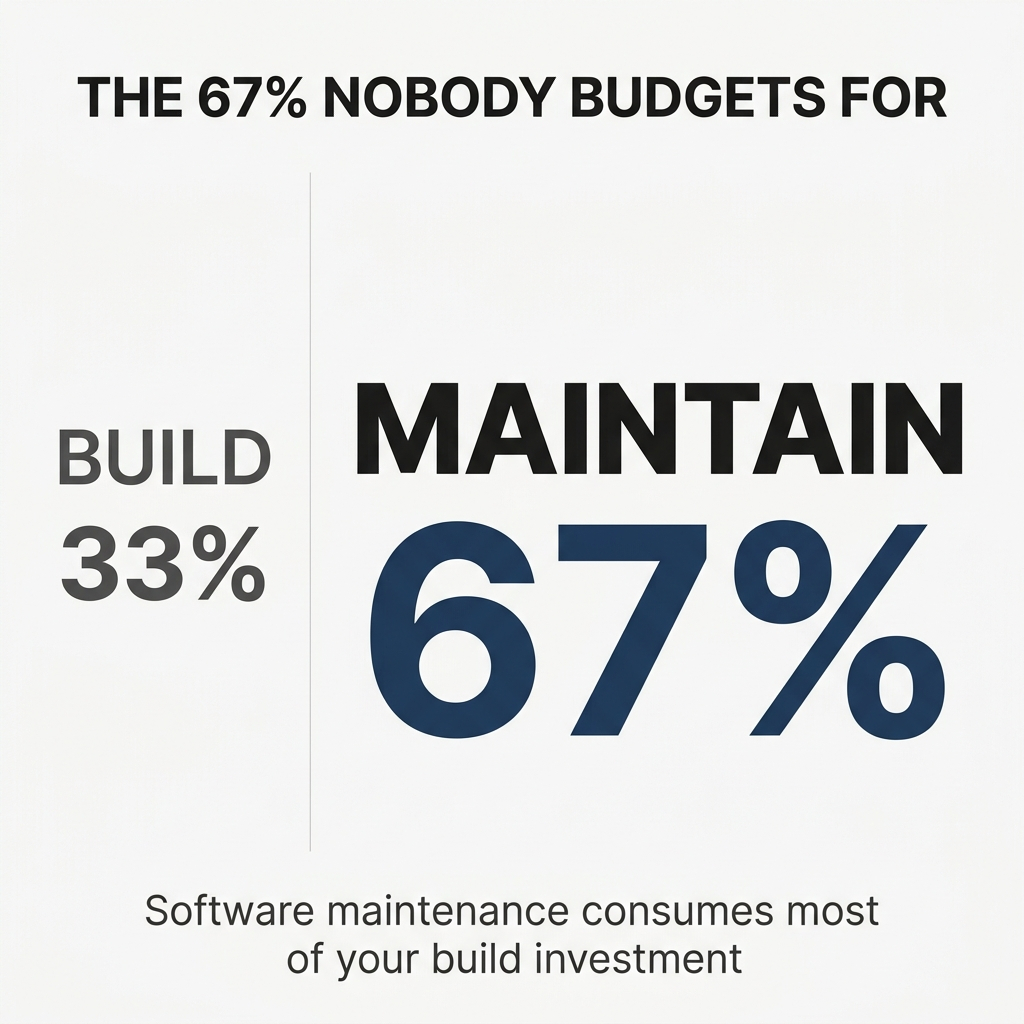
Software maintenance operations consume approximately 67% of the total software development life cycle cost. The build decision is really just 33% of the story.
Companies waste up to 40% of their development time dealing with technical debt—nearly half of engineering effort going into fixing yesterday's decisions instead of building tomorrow's innovations.
The question is not whether you can build it. The question is whether you should own the ongoing burden of keeping it current, trusted, and integrated as the market moves.
Most teams underestimate what it takes to turn a working prototype into production-grade infrastructure that the organization can rely on for years.
That's the Engineering Tax. And it compounds.