
Retrieval Without Relationships Is Just Expensive Search

I've spent three decades watching consulting firms lose what makes them valuable.
The expertise walks out the door. The context evaporates. The institutional memory that took years to build vanishes in months.
So when RAG showed up promising to solve knowledge access, I paid attention. Everyone did. Vector databases, semantic search, retrieval-augmented generation—the whole stack looked like the answer we'd been waiting for.
Except it wasn't.
Because retrieval without relationships is just sophisticated search. And search has never been the problem.
The EMNLP Research That Changes Everything
Here's what caught my eye: research presented at EMNLP 2024 showed that using knowledge graphs as reasoning guidelines improved performance by up to 14.03% compared to standard RAG approaches.
The key insight? Using reasoning chains as context was often sufficient to correctly answer questions. You didn't need the entire document. You needed the relationships.
This matters because it exposes the fundamental flaw in how most organizations are deploying AI right now.
What Standard RAG Actually Does
Let me be direct about the limitations.
Low precision. RAG systems match queries based on broad similarities rather than specific details. When you search for information on a particular topic, you get documents that mention the subject but fail to capture the specific context or nuances you actually need.
Low recall. The system fails to retrieve all relevant chunks. It's not that the information doesn't exist—it's that the retrieval mechanism can't find it because it's looking for similarity, not relationships.
Outdated information. The LLM gets passed stale data, leading to hallucinations and inaccurate responses. There's no mechanism to understand which information is current, which is superseded, or how different pieces of knowledge relate over time.
This isn't a configuration problem. It's an architectural one.
Why Relationships Change the Game
Vector databases excel at identifying semantically similar objects. They're good at what they do.
But they fall short in capturing the underlying knowledge that knowledge graphs preserve.
Knowledge graphs excel at answering complex queries that involve hopping through several entities and relationships. They efficiently navigate graph structures to provide precise answers, making them ideal for applications that require detailed insights or multi-step reasoning.
The benchmarks tell the story. Query accuracy improves 2.8x with the addition of knowledge to complex vector queries.
That's not incremental. That's fundamental.
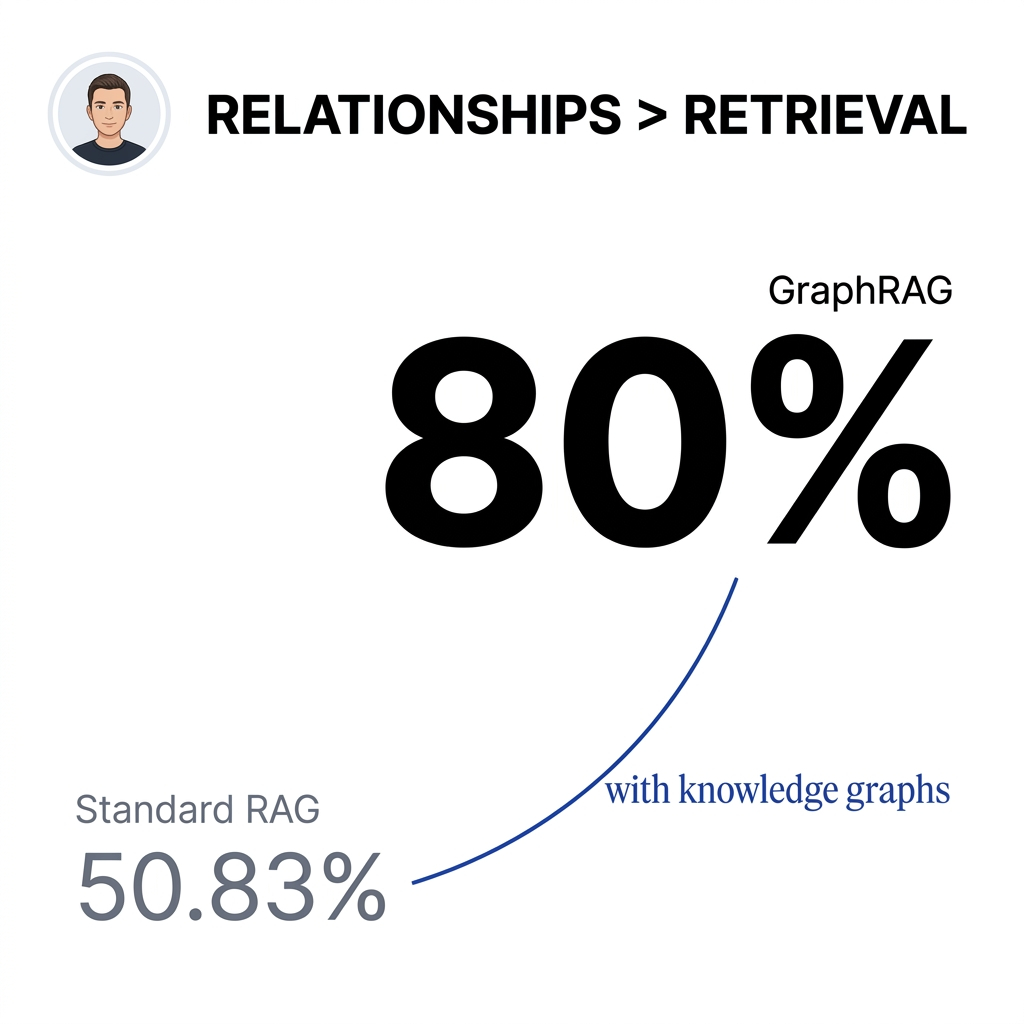
The GraphRAG Performance Gap
I track the benchmarks because they reveal what's actually working in production environments.
GraphRAG achieved 80% correct answers versus 50.83% for traditional RAG in Lettria's AWS benchmark from December 2024. That's a 3.4x improvement on enterprise benchmarks.
On global questions requiring comprehensive understanding, GraphRAG scored 72-83% on comprehensiveness metrics.
Writer Knowledge Graph hit 86.31% on the RobustQA benchmark, significantly outperforming competition which scored between 75.89% and 32.74%. And they did it with the fastest average response time—less than 0.6 seconds.
Speed with accuracy. That's what happens when you build on the right foundation.
The Explainability Advantage
Here's what matters in professional services: you need to explain your reasoning.
In financial services and fraud detection, institutions need to explain why certain transactions are flagged as suspicious. In consulting, you need to show clients how you arrived at a recommendation. In legal work, you need to trace the logic from precedent to conclusion.
Knowledge graphs offer transparent reasoning paths. They enable explicit relationships to be stored and queried against, reducing hallucinations and increasing accuracy through context injection.
This isn't a nice-to-have feature. It's the foundation of trust.
When I built Experio, I made transparency non-negotiable. Full traceability isn't a feature we added—it's the architecture we started with. Because in an industry drowning in black-box AI, explainability is what separates tools from infrastructure.
When Relationships Matter Most
A knowledge graph is ideal for RAG systems that have structured or interconnected data.
It excels in scenarios where the 'how' is just as important as the 'why'—medical research, financial compliance, analytics, business data. It enables multi-hop reasoning by modeling entities such as people, organizations, roles, and products.
Understanding the relationships between these entities helps LLMs trace how the answer was retrieved, not just the information itself.
This is the difference between finding a document and understanding a domain.
Vector databases are ideal for broad similarity matching and unstructured data retrieval. Knowledge graphs excel when context windows are limited and when multi-hop relationships, factual accuracy, and complex hierarchical structures are required.
Graphs preserve relationships over time, maintaining richer context compared to isolated vector embeddings. This leads to better handling of long or interconnected information without losing important details.
The Institutional Memory Connection
I've watched expertise evaporate through acquisitions, transitions, retirements, and simple organizational drift for thirty years.
The pattern is consistent: firms treat memory as disposable. They accept that 30% of billable time vanishes into searching, asking, and recreating. They normalize the loss of what people knew when they leave.
This is a design failure, not a cost of doing business.
Knowledge graphs change this because they preserve what vector databases can't: the relationships that give information meaning. The connections between concepts. The evolution of thinking over time. The context that turns data into expertise.
When you build on knowledge graphs, you're not just improving search results. You're installing organizational memory where none existed.
What This Means for Professional Services
The firms that adopt knowledge graph infrastructure now get an advantage.
The firms that wait get disruption.
Because the market is moving from "who has the best search" to "who has the best reasoning." From "who can find information fastest" to "who can preserve and deploy collective intelligence."
Vector databases will remain useful for certain applications. But when you need to understand relationships, trace reasoning, maintain accuracy, and preserve institutional memory—you need graph infrastructure.
The EMNLP research confirms what I've seen building Experio: knowledge graphs as reasoning guidelines fundamentally change what's possible.
Everyone's doing retrieval. But retrieval without relationships is just sophisticated search.
And search has never been the problem.
The Real Question
The question isn't whether knowledge graphs perform better than standard RAG. The benchmarks settled that.
The question is whether your organization is ready to treat memory as infrastructure instead of nostalgia.
Because the firms that figure this out first won't just move faster. They'll think differently.
And in knowledge-intensive industries, that's the only advantage that compounds.