
When RAG Systems Forget What They Know

I started noticing something strange when talking to enterprise customers about their AI deployments.
They'd invested in RAG systems—Retrieval-Augmented Generation tools that promise to turn organizational knowledge into instant answers. Tools like Microsoft Copilot 365, Gemini Enterprise, Notebook LM, Glean and many more use RAG as the center of their technology. The demos looked great. The first few hundred documents worked beautifully.
Then everything quietly fell apart.
One prospective client wanted to analyze 10,000 contracts and compare specific clauses across them. Standard consulting work. The kind of task that should be perfect for AI.
Up to 200-300 documents, the system performed exactly as expected. Clean results. Accurate comparisons. Fast turnaround.
Above that number, documents started disappearing from results. Not randomly. Not because of capacity limits. The system wasn't overloaded—it was experiencing something I'd later understand as semantic collapse.
The Math Nobody Talks About
Here's what most vendors won't tell you about RAG performance at scale.
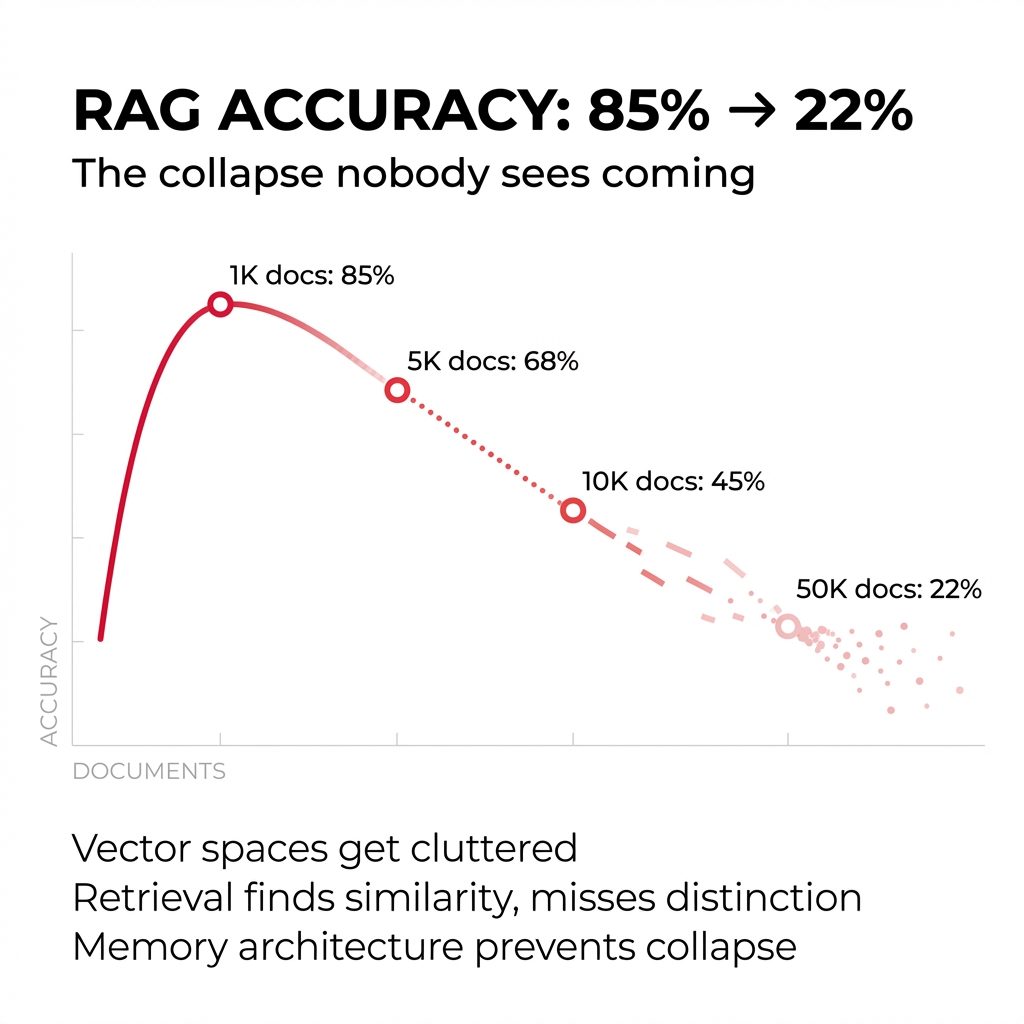
According to Stanford research, RAG systems follow a predictable degradation curve:
- 1,000 documents: 85% accuracy
- 5,000 documents: 68% accuracy
- 10,000 documents: 45% accuracy
- 50,000 documents: 22% accuracy
This isn't gradual decay. It's structural failure disguised as scale.
The question complexity didn't matter. Simple queries failed just as often as complex ones. We kept adding documents, and performance kept dropping—regardless of what we asked.
That's when I realized this wasn't a bug. It was the architecture revealing its limitations.
What Semantic Collapse Actually Looks Like
Semantic collapse happens when retrieved context stops functioning as context.
The system sees text. It retrieves documents. It generates answers that look informed and even include citations.
But the thinking underneath has thinned out.
As AI Competence documents, relationships flatten, hierarchy disappears, and causes blur into a single semantic surface. You get answers that sound confident but lack depth. Different questions yield similar, generic explanations.
The model retrieved information but lost the ability to reason with it.
In that contract analysis project, we'd ask about specific indemnification clauses in healthcare agreements. The system would return clauses from software licensing contracts instead—semantically similar language, completely wrong context.
The words matched. The meaning didn't.
The Lost in the Middle Problem
Stanford researchers identified another pattern: when models receive too much context, they fail to identify which information actually matters.
Even when the answer is technically present.
This is particularly pronounced when critical data gets buried in the middle of large text blocks. The system overlooks important details because it can't distinguish signal from noise at scale.
You might achieve 0.85 precision at the retrieval stage, but if the critical document lands at position 15, the language model never sees it. The answer exists in the system. The system just can't find it.
Why Vector Similarity Creates an Illusion
Most RAG systems rely on vector embeddings to find relevant documents.
The logic seems sound: convert text into mathematical representations, then retrieve documents with similar vectors when someone asks a question.
But embeddings optimize for similarity, not intent or logic.
At scale, this creates dense semantic neighborhoods where unrelated passages coexist. Modern encoders can't organize large document sets in vector spaces effectively—the encoder can only fit so much information into a vector space before it gets cluttered.
There's a difference between a space being able to fit information and that information being meaningfully organized.
Think about it this way: if you're searching for "force majeure clauses in pandemic scenarios," the system might return every document mentioning "force majeure" and "pandemic" without understanding that you need clauses specifically addressing how pandemics trigger force majeure provisions.
The semantic similarity is high. The contextual relevance is zero.
Production Breaks RAG in Ways Demos Never Reveal
Demo environments are clean. Controlled. Small.
Production is messy.
A Redis engineering analysis found that scale exposes cascading failures most organizations don't see coming. Costs spiral from redundant queries. Quality silently degrades while manual testing falls further behind.
RAG systems have multiple stages: chunking, retrieval, reranking, generation. If any stage fails, you get cascading failures down the entire system.
Most critically, failure at the ingestion layer causes most hallucinations. Models generate confidently incorrect answers because the retrieval layer returns ambiguous or outdated knowledge.
You're not dealing with a single point of failure. You're managing a chain where each link can break independently.
The Chunking Bottleneck Nobody Mentions
Here's something most vendors skip over: semantic chunking determines RAG accuracy more than embeddings or models.
When RAG systems split meaning mid-thought, they behave like readers forced to recall half sentences. Token-based chunks often cut sentences, tables, or explanations apart.
Context loss becomes inevitable.
These breaks dilute embeddings—each vector carries less signal and more noise. Precision drops fast, and you can't fix it by upgrading your language model or adding more compute.
The damage happens before the model ever sees the text.
The Metrics That Actually Matter
Most organizations track the wrong indicators.
Vendors highlight speed, document count, and token limits. Those are vanity metrics.
What you need to measure:
Context relevance: Did retrieval find the right documents?
Groundedness: Do generated responses stay true to retrieved context without inventing facts?
Answer relevance: Does the output address what users actually asked?
Miss any of these dimensions and you're optimizing the wrong bottleneck.
Without evaluation baselines and regression testing, changes will silently degrade quality for weeks before users report problems. By then, trust has eroded and adoption stalls.
Why Long Context Windows Don't Solve This
Some people assume that expanding context windows fixes the semantic collapse problem.
It doesn't.
Even with Gemini's 2 million token context window, you can only process approximately 10 standard annual financial reports. Databricks research found that many models show reduced performance at long context—failing to follow instructions or producing repetitious outputs.
Models also suffer from position bias. They perform better when key insights appear near the beginning or end of a document but struggle to retrieve critical details buried in the middle.
OpenAI recommends including only the most relevant information to prevent the model from overcomplicating its response.
More context doesn't mean better reasoning. Often, it means worse performance.
Memory vs. Retrieval: A Structural Difference
This is where most organizations misunderstand what they're building.
RAG treats knowledge as something to retrieve on demand. You ask a question, the system searches, it returns results.
But organizational knowledge isn't a search problem. It's a memory problem.
Memory is infrastructure. It persists. It maintains relationships. It understands context not just through similarity but through accumulated understanding of how information connects across your organization.
When someone leaves your firm, their expertise shouldn't evaporate. When a project ends, the lessons learned shouldn't get buried in a shared drive. When a client asks about past work, you shouldn't need to reconstruct context from scratch.
That's the difference between retrieval and memory.
Retrieval finds documents. Memory understands what they mean in relation to everything else your organization knows.
The Knowledge Decay Problem
Every enterprise RAG system eventually faces the same reality: yesterday's knowledge becomes today's liability.
Traditional retrieval returns the most semantically similar documents without considering staleness. A query might retrieve a highly relevant document last updated 60 days ago while a more recent version sits untouched.
The problem isn't architecture. It's that most RAG implementations treat knowledge bases like static artifacts instead of living systems requiring constant care.
This is the knowledge decay problem, and it's silently destroying enterprise RAG credibility across industries.
Why Transparency Becomes Critical
In an industry drowning in black-box AI, auditability isn't a compliance feature.
It's the only way to detect and prevent semantic collapse before it erodes institutional trust.
When a RAG system gives you an answer, you need to know:
- Which documents it retrieved
- Why it chose those documents
- What reasoning process it followed
- Where potential gaps exist in its knowledge
Without transparency, you can't diagnose failures. You can't improve performance. You can't trust the system when stakes are high.
Professional services firms operate on expertise and precision. A system that can't explain its reasoning is a system you can't rely on for client-facing work.
What This Means for Professional Services Firms
If you're currently scaling a RAG implementation, you need to understand what you're actually building.
You're not just deploying a tool. You're installing infrastructure that will either preserve or erode your institutional knowledge.
The hidden costs of tolerating degraded precision compound quickly:
Billable time lost to searching for information the system should have found.
Client trust damaged when AI-generated insights prove unreliable.
Expertise wasted as senior people spend time validating outputs instead of doing high-value work.
Competitive advantage lost as your knowledge becomes less accessible than your competitors'.
The firms that get memory architecture right from the start gain a structural advantage. The firms that treat it as a feature addition face disruption.
Building Different Infrastructure
At Experio, we built from the problem backward.
The problem wasn't that RAG systems needed better embeddings or faster retrieval. The problem was that they were never designed to remember at institutional scale.
So we built infrastructure that treats organizational knowledge as persistent memory—not on-demand search.
Systems that understand context through accumulated learning, not just vector similarity.
Architecture that maintains transparency so you can see exactly how decisions get made.
This isn't an incremental improvement on RAG. It's fundamentally different infrastructure built on the principle that memory is infrastructure, not nostalgia.
The firms adopting now get an advantage. The firms waiting get disruption.
Semantic collapse isn't a technical problem you can patch. It's a structural limitation that reveals what happens when you build retrieval systems and call them memory.
The question isn't whether your RAG system will hit this threshold.
The question is whether you'll recognize it when you do.